linux 의 user area 에서 사용하는 semaphore 에 대한 글
원문 : http://www.joinc.co.kr/modules/moniwiki/wiki.php/Site/system_programing/IPC/semaphores
원문2 : http://www.hanbit.co.kr/network/view.html?bi_id=1399
![[-]](http://www.joinc.co.kr/modules/moniwiki/imgs/plugin/arrup.png "[-]")
1 세마포어란 무엇인가
세마포어(Semaphores)를 비록 IPC(:12)설비중의 하나로 분류하긴 했지만, 다른 파이프, 메시지큐(:12), FIFO(:12)등과는 좀다르다. 다른 IPC 설비들이 대부분 프로세스간 메시지 전송을 그 목적으로 하는데 반해서 세마포어는 프로세스간 데이타를 동기화 하고 보호하는데 그목적이 있다. POSIX(:12) 세마포어와 System V 세마포어 모두를 다룰 계획이다.
프로세스간 메시지 전송을 하거나, 혹은 공유메모리(:12)를 통해서 특정 데이타를 공유하게 될경우 발생하는 문제가, 공유된 자원에 여러개의 프로세스가 동시에 접근을 하면 안되며, 단지 한번에 하나의 프로세스만 접근 가능하도록 만들어줘야 할것이다. 이것은 쓰레드에서 메시지간 동기화를 위해서 mutex(:12) 를 사용하는것과 같은 이유이다.
하나의 데이타에 여러개의 프로세스가 관여할때 어떤 문제점이 발생할수 있는지 간단한 예를 들어보도록 하겠다.
int count=100; A 프로세스가 count를 읽어온다. 100 B 프로세스가 count를 읽어온다. 100 B 프로세스가 count를 1 증가 시킨다. 101 A 프로세스가 count를 1 증가 시킨다. 101count는 공유자원(공유메모리 같은)이며 A와 B 프로그램이 여기에 대한 작업을 한다. A가 1을 증가 시키고 B가 1을 증가시키므로 최종 count 값은 102 가 되어야 할것이다. 그러나 A 가 작업을 마치기 전에 B가 작업을 하게 됨으로 엉뚱한 결과를 보여주게 되었다. 위의 문제를 해결하기 위해서는 count 에 A가 접근할때 B프로세스가 접근하지못하도록 block 시키고, A가 모든 작업을 마쳤을때 B프로세스가 작업을 할수 있도록 block 를 해제 시키면 될것이다.
우리는 세마포어를 이용해서 이러한 작업을 할수 있다. 한마디로 줄여서 세마포어는 "여러개의 프로세스에 의해서 공유된는 자원의 접근제어를 위한 도구" 이다.
1.1 세마포어의 작동원리
세마포어는 상호 배제알고리즘으로 임계 영역을 만들어서 자원을 보호한다. 작동원리는 매우 간단하다. 차단을 원하는 자원에대해서 세마포어를 생성하면 해당자원을 가리키는 세마포어 값이 할당된다. 이 세마포어값을 검사해서 임계영역에 접근할 수 있는지를 결정하게 된다.
세마포어 값이 0이면 이 자원에 접근할수 없으며, 0보다 큰 정수면 해당 정수의 크기만큼의 프로세스가 자원에 접근할수 있다라는 뜻이 된다. 그러므로 우리는 접근제어를 해야하는 자원에 접근하기 전에 세마포어 값을 검사해서 값이 0이면 자원을 사용할수 있을때까지 기다리고, 0보다 더 크면(1이라고 가정하자) 자원에 접근하게 된다. 자원에 접근하면 세마포어 값을 1 감소해서 세마포어 값을 0으로 만들고 다른 프로세스가 자원에 접근할수 없도록 한다. 자원의 사용이 끝나면 세마포어 값을 다시 1증가시켜서 다른 프로세스가 자원을 사용할수 있도록 만들어주면 된다.
이렇게 보호되어야 하는 자원과 연산을 포함한 영역을 임계 영역 (Critical Section)이라고 한다. 세마포어는 임계 영역에 진입하기 위한 키이다. 공용 사물함을 사용하기 위한 키의 작동방식을 생각하면 된다.

세마포어의 이론적인 원리는 원자화문서를 참고하자.
2 System V 세마포어
2.1 세마포어의 사용
세마포어의 사용은 위의 작동원리를 그대로 적용한다. 즉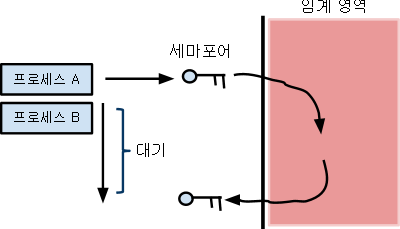
- 임계 영역을 설정한다.
- 임계 영역에 진입하기전에 세마포어 값을 확인한다.
- 세마포어 값이 0보다 크면 세마포어를 가져온다. 세마포어를 가져왔으니 (커널의 입장에서)세마포어가 1감소 한다.
- 세마포어 값이 0이면 값이 0보다 커질때까지 block 되며, 0보다 커지게 되면 2번 부터 시작하게 된다.
위의 작업을 위해서 Unix 는 다음과 같은 관련함수들을 제공한다.
#include <sys/types.h> #include <sys/ipc.h> #include <sys/sem.h> int semget(key_t key, int nsems, int semflg); int semop (int semid, struct sembuf *sops, unsigned nsops); int semctl(int semid, int semnum, int cmd, union semun arg);
2.2 세마포어의 관리
세마포어는 그 특성상 원자화(:12)된 연산을 필요로 한다. 원자화된 연산은 유저레벨의 함수에서는 제공하기가 힘들므로, 세마포어 정보는 커널에서 전용 구조체를 이용해서 관리하게 된다. 다음은 커널에서 세모포어 정보를 유지하기 위해서 관리하는 구조체인 semid_ds 구조체의 모습이다.
semid_ds는 /usr/include/bits/sem.h 에 선언되어 있다. (이것은 리눅스에서의 경우로 Unix 버젼에 따라서 위치와 멤버변수에 약간씩 차이가 있을수 있다)
struct semid_ds
{
struct ipc_perm sem_perm;
__time_t sem_otime;
unsigned long int __unused1;
__time_t sem_ctime;
unsigned long int __unused2;
unsigned long int sem_nsems;
unsigned long int __unused3;
unsigned long int __unused4;
};
sem_perm 은 세마포어에 대한 퍼미션으로 일반 파일퍼미션과 마찬가지의 기능을 제공한다. 즉 현재 세마포어 구조체에 접근할수 있는 사용자권한을 설정한다. sem_nsems 는 생성할수 있는 세마포어의 크기이다. sem_otime 은 마지막으로 세마포어관련 작업을 한 시간(semop 함수를 이용)이며, sem_ctim 은 마지막으로 구조체 정보가 바뀐 시간이다.2.3 semget 을 이용해서 세마포어를 만들자.
세마포어의 생성혹은 기존에 만들어져 있는 세마포어에 접근하기 위해서 유닉스에서 는 semget(2)를 제공한다. 첫번째 매개변수는 세마포어의 유일함을 보장하기 위해서 사용하는 키값이다. 우리는 이 키값으로 유일한 세마포어를 생성하거나 접근할 수 있다. 새로 생성되거나 기존의 세마포어에 접근하거나 하는것은 semflg 를 통해서 제어할수 있다. 다음은 semflg에서 사용할 수 있는 값이다.
- IPC_CREAT 만약 커널에 해당 key 값으로 존재하는 세마포어가 없다면, 새로 생성 한다.
- IPC_EXCL IPC_CREAT와 함께 사용하며, 해당 key 값으로 세마포어가 이미 존재한다면 실패값을 리턴한다.
만약 IPC_CREAT 만 사용할경우 해당 key 값으로 존재하는 세마포어가 없다면, 새로 생성하고, 이미 존재한다면 존재하는 세마포어의 id 를 넘겨준다. IPC_EXCL을 사용하면 key 값으로 존재하는 세마포어가 없을경우 새로 생성되고, 이미 존재한다면 존재하는 id 값을 돌려주지 않고 실패값(-1)을 되돌려주고, errno 를 설정한다.
nsems 은 세마포어 셋 즉 배열의 크기다. 이값은 최초 세마포어를 생성하는 생성자의 경우에 크기가 필요하다(보통 1). 그외에 세마포어에 접근해서 사용하는 소비자의 경우에는 세마포어를 만들지 않고 단지 접근만 할뿐임으로 크기는 0이 된다.
이상의 내용을 정리하면 semget 은 아래와 같이 사용할수 있을것이다.
만약 최초 생성이라면
sem_num = 1;
그렇지 않고 만들어진 세마포어에 접근하는 것이라면
sem_num = 0;
sem_id = semget(12345, sem_num, IPC_CREAT|0660)) == -1)
{
perror("semget error : ");
return -1;
}
semget 은 성공할경우 int 형의 세마포어 식별자를 되돌려주며, 모든 세마포어에 대한 접근은 이 세마포어 실별자를 사용한다.위의 코드는 key 12345 를 이용해서 세마포어를 생성하며 퍼미션은 0660으로 설정된다. 세마포어의 크기는 1로 잡혀 있다(대부분의 경우 1).
만약 기존에 key 12345 로 이미 만들어진 세마포어가 있다면 새로 생성하지 않고 기존의 세마포어에 접근할수 있는 세마포어 식별자를 되돌려주게 되고, 커널은 semget 를 통해 넘어온 정보를 이용해서 semid_ds 구조체를 세팅한다.
예제: semget.c
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
int main()
{
int semid;
semid = semget((key_t)12345, 1, 0666 | IPC_CREAT);
}
이제 위의 코드를 컴파일해서 실행시키고 나서 실제로 세마포어 정보가 어떻게 바뀌였는지 확인해 보도록 하자. 커널에서 관리되는 ipc 정보를 알아보기 위해서는 ipcs(8)라는 도구를 이용하면 된다.[root@localhost test]# ipcs -s ------ Semaphore Arrays -------- key semid owner perms nsems status 0x00003039 0 root 666 1
0x00003039 은 key 12345 의 16진수 표현이다. 퍼미션은 666으로 되어 있고 semget 를 통해서 제대로 설정되어 있음을 알수 있다.
2.4 세마포어를 이용해서 접근제어 하기
이제 semget을 통해서 세마포어를 새로 만들고 얻었으니, 이제 실제로 세마포어상태를 검사해서 접근제어를 해보도록하자. 접근제어는 세마포어를 얻거나 되돌려 주는 방식으로 이루어진다. semop함수로 이러한 일들을 할 수 있다.
int semop(int semid, struct sembuf *sops, unsigned nsops);
semop의 첫번째 semid 는 semget 을 통해서 얻은 세마포어 식별자이다. 2번째 아규먼트는 struct sembuf 로써, 어떤 연산을 이루어지게 할런지 결정하기 위해서 사용된다. 구조체의 내은 다음과 같으며, sys/sem.h 에 선언되어 있다.
struct sembuf
{
short sem_num; // 세마포어의수
short sem_op; // 세마포어 연산지정
short sem_flg; // 연산옵션(flag)
}
sem_num 멤버는 세마포어의 수로 여러개의 세마포어를 사용하지 않는다면(즉 배열이 아닐경우) 0을 사용한다. 배열의 인덱스 사이즈라고 생각하면 될것이다. 보통의 경우 하나의 세마포어를 지정해서 사용하므로 0 이 될것이다.sem_op 를 이용해서 실질적으로 세마포어 연산을 하게 되며, 이것을 이용해서 세마포어 값을 증가시키거나 감소 시킬수 잇다. sem_op 값이 양수일 경우는 자원을 다 썼으니, 세마포어 값을 증가시키겠다는 뜻이며, 음수일 경우에는 세마포어를 사용할것을 요청한다라는 뜻이다.음수일 경우 세마포어값이 충분하다면 세마포어를 사용할수 있으며, 커널은 세마포어의 값을 음수의 크기의 절대값만큼을 세마포어에서 빼준다. 만약 세마포어의 값이 충분하지 않다면 세번째 아규먼트인 sem_flg 에 따라서 행동이 결정되는데, sem_flg 가 IPC_NOWAIT로 명시되어 있다면, 해당영역에서 기다리지 않고(none block) 바로 에러코드를 리턴한다. 그렇지 않다면 세마포어를 획득할수 있을때까지 block 되게 된다.
sem_flg 는 IPC_NOWAIT 와 SEM_UNDO 2개의 설정할수 있는 값을가지고 있다. IPC_NOWAIT 는 none block 모드 지정을 위해서 사용되며, SEM_UNDO 는 프로세스가 세마포어를 돌려주지 않고 종료해버릴경우 커널에서 알아서 세마포어 값을 조정(증가) 할수 있도록 만들어 준다.
설명이 아마 애매모호한면이 있을것이다. 간단한 상황을 예로 들어서 설명해 보겠다.
현재 세마포어 값이 1 이라고 가정하자. 이때 A 프로세스가 semop 를 통해서 세마포어에 접근을 시도한다. A는 접근을 위해서 sem_op 에 -1 을 세팅한다. 즉 세마포어 자원을 1 만큼 사용하겠다라는 뜻이다. 현재 준비된 세마포어 값은 1로 즉시 사용할수 있으므로, A는 자원을 사용하게 되며, 커널은 세마포어 값을 1 만큼 감소시킨다. 이때 B 라는 프로세스가 세마포어 자원을 1 만큼 사용하겠다라고 요청을 한다. 그러나 지금 세마포어 값은 0 이므로 B는 지금당장 세마포어 를 사용할수 없으며, 기다리거나, 에러값을 리턴 받아야 한다(IPC_NOWAIT). B는 자원 사용가능할때까지 기다리기로 결정을 했다. 잠수후 A는 모든 작업을 다마쳤다. 이제 세마포어를 되돌려줘야 한다. sem_op 에 1 을 세팅하면, 커널은 세마포어 값을 1증가시키게 된다. 드디어 기다리던 B가 세마포어 자원을 사용할수 있는 때가 도래했다. 이제 세마포어 값은 1이 므로 B는 세마포어를 획득하게 된다. 커널은 세마포어 값을 1 감소 시킨다. B는 원하는 작업을 한다. ... ...
2.5 세마포어 조작
semctl 이란 함수를 이용해서 우리는 세마포어를 조정할수 있다.
semctl 은 semid_ds 구조체를 변경함으로써 세마포어의 특성을 조정한다.
첫번째 아규먼트인 semid 는 세마포어 식별자다. semnum 은 세마포어 배열에서 몇 번째 세마포어를 사용할지를 선택하기 위해서 사용한다. 세마포어의 크기가 1이라면 0이 된다. (배열은 0번 부터 시작하기 때문) cmd 는 세마포어 조작명령어 셋으로 다음과 같은 조작명령어들을 가지고 있다. 아래는 그중 중요하다고 생각되는 것들만을 설명하였다. 더 자세한 내용은 semctl 에 대한 man 페이지를 참고하기 바란다.
- IPC_STAT세마포어 상태값을 얻어오기 위해 사용되며, 상태값은 arg 에 저장된다.
- IPC_RMID세마포어 를 삭제하기 위해서 사용한다.
- IPC_SETsemid_ds 의 ipc_perm 정보를 변경함으로써 세마포어에 대한 권한을 변경한다.
2.6 예제
지금까지 익혔던 내용을 토대로 간단한 예제프로그램을 만들어보겠다. 예제의 상황은 하나의 파일에 2개의 프로세스가 동시에 접근하고자 하는데에서 발생한다. 파일에는 count 숫자가 들어 있으며, 프로세스는 파일을 열어서 count 숫자를 읽어들이고, 여기에 1을 더해서 다시 저장하는 작업을한다. 이것을 세마포어를 통해서 제어하지 않으면 위에서 설명한 문제가 발생할것이다.
위의 문제를 해결하기 위해서는 파일을 열기전에 세마포어를 설정해서 한번에 하나의 프로세스만 접근가능하도록 하면 될것이다. 모든 파일작업을 마치게 되면, 세마포어 자원을 돌려줌으로써, 비로서 다른 프로세스가 접근가능하게 만들어야 한다.
예제: sem_test
#include <sys/types.h>
#include <sys/sem.h>
#include <sys/ipc.h>
#include <stdio.h>
#include <unistd.h>
#define SEMKEY 2345
union semun
{
int val;
struct semid_ds *buf;
unsigned short int *array;
};
static int semid;
int main(int argc, char **argv)
{
FILE* fp;
char buf[11];
char count[11];
union semun sem_union;
// open 과 close 를 위한 sembuf 구조체를 정의한다.
struct sembuf mysem_open = {0, -1, SEM_UNDO}; // 세마포어 얻기
struct sembuf mysem_close = {0, 1, SEM_UNDO}; // 세마포어 돌려주기
int sem_num;
memset(buf, 0x00, 11);
memset(count, 0x00, 11);
// 아규먼트가 있으면 생성자
// 그렇지 않으면 소비자이다.
if (argc > 1)
sem_num = 1;
else
sem_num = 0;
// 세마포설정을 한다.
semid = semget((key_t)234, sem_num, 0660|IPC_CREAT);
if (semid == -1)
{
perror("semget error ");
exit(0);
}
// 세마포어 초기화
sem_union.val = 1;
if ( -1 == semctl( semid, 0, SETVAL, sem_union))
{
printf( "semctl()-SETVAL 실행 오류\n");
return -1;
}
// counter.txt 파일을 열기 위해서 세마포어검사를한다.
if(semop(semid, &mysem_open, 1) == -1)
{
perror("semop error ");
exit(0);
}
if ((fp = fopen("counter.txt", "r+")) == NULL)
{
perror("fopen error ");
exit(0);
}
// 파일의 내용을 읽은후 파일을 처음으로 되돌린다.
fgets(buf, 11, fp);
rewind(fp);
// 개행문자를 제거한다.
buf[strlen(buf) - 1] = 0x00;
sprintf(count, "%d\n", atoi(buf) + 1);
printf("%s", count);
// 10초를 잠들고 난후 count 를 파일에 쓴다.
sleep(10);
fputs(count,fp);
fclose(fp);
// 모든 작업을 마쳤다면 세마포어 자원을 되될려준다
semop(semid, &mysem_close, 1);
return 1;
}
코드는 매우 간단하지만, 세마포어에 대한 기본적인 이해를 충분히 할수 있을만한 코드이다. 생성자와 소비자의 분리는 프로그램에 넘겨지는 아규먼트를 이용했다. 모든 작업을 마치면 테스트를 위해서 10초를 기다린후에 세마포어를 돌려주도록 코딩되어 있다.우선 count 를 저장할 파일 counter.txt 를 만들고 여기에는 1을 저장해 놓는다. 그다음 ./sem_test 를 실행시키는데, 최초에는 생성자를 만들어야 하므로 아규먼트를 주어서 실행시키고, 그다음에 실행시킬때는 소비자가 되므로 아규먼트 없이 실행하도록 하자. 다음은 테스트 방법이다.
[root@coco test]# ./sem_test 1& [1] 3473 36 [root@coco test]# ./sem_test위 코드를 실행해보면 ./sem_test 1 이 세마포어자원을 돌려주기 전까지 ./sem_test 가 해당영역에서(세마포어 요청하는 부분) 블럭되어 있음을 알수 있고, 충돌없이 count가 잘되는것을 볼수 있을것이다.
세마포어는 커널에서 관리하는데 세마포어를 사용하는 프로세스가 없다고 하더라도 semctl 을 이용해서 제거하지 않는한은 커널에 남아있게 된다. 세마포어 정보를 제거하기 위해서는 semctl 연산을 하든지, 컴퓨터를 리붓 시커거나, ipcrm(8)이란 도구를 사용해서 제거시켜 줘야 한다.
3 POSIX 세마포어
POSIX 규격을 따르는 새로운 세마포어 인터페이스로 전통적인 System V 인터페이스에 비해서 좀 더 명확하다. 또한 세마포어 집합이란 개념이 없는데, 덕분에 이해하기가 수월해진 것 같다.
POSIX 세마포어 함수를 사용하기 위해서는 -lrt로 리얼타임 라이브러리를 링크해야 한다.
# gcc -lrt sem_test sem_test.c
3.1 세마포어 만들기
세마포어는 "익명 세마포어 (unnamed-)"와 "이름 있는 세마포어 (named-)"가 있다.
익명 세마포어는 sem_init로 만든다.
#include <semaphore.h> int sem_init(sem_t *sem, int pshared, unsigned int value);
- sem : 초기화할 세마포어 객체
- pshared : 0이 아니면 프로세스들 간에 세마포어를 공유한다. 0이면 프로세스 내부에서만 사용한다.
- value : 세마포어 초기 값
sem_init(&sem_name, 0, 10);
이름 있는 세마포어는 sem_open으로 만든다.
sem_t* sem_open(const char* name, int oflag, mode_t mode, unsigned int value);이름 있는 세마포어는 파일로 만들어지기 때문에, 파일 이름과 권한설정이 필요하다. 세마포어 파일은 /dev/shm에 만들어진다. 그러므로 /dev/shm을 마운트 시켜줘야 한다.
# mount /dev/shm
3.2 세마포어 얻기 (기다리기)
세마포어를 얻을 때까지 기다린다.
sem_wait(sem_t *sem); sem_trywait(sem_t *sem); sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);sem_wait함수는 만약 세마포어 값이 0보다 크면 프로세스는 세마포어를 얻고 세마포어를 감소하고 즉시 반환한다. 세마포어값이 0이라면 세마포어가 0보다 더 커지거나 시그널이 발생할 때까지 대기한다.
sem_trywait는 즉시 세마포어를 감소시키고 반환하는 것을 제외하고는 sem_wait와 같다.
timeout시간동안의 제한시간을 가진다는 것을 제외하고는 sem_wait함수와 같다. stimespec구조체를 이용해서 초+나노초 수준에서 제한시간을 지정할 수 있다.
struct timespec
{
time_t tv_sec; /* Seconds */
long tv_nsec; /* Nano Seconds */
};
제한 시간내에 세마포어를 얻지 못하면 errno 값으로 ETIMEDOUT을 설정하고 반환한다.3.3 세마포어 정보 가져오기
#include <semaphore.h> int sem_getvalue(sem_t *sem, int *sval);
현재 세마포어의 값을 알아온다. 값은 sval로 넘어온다.
3.4 세마포어 되돌려주기
sem_pos함수로 세마포어를 되돌려준다. 세마포어 값이 하나 증가한다.
#include <semaphore.h> int sem_post(sem_t *sem);
3.5 세마포어 삭제
sem_unlink함수로 세마포어를 삭제한다. 이름있는 세마포어를 삭제하고자 할때 사용한다.
#include <semaphore.h> int sem_unlink(const char *name);
3.6 POSIX 익명 세마포어 예제
뮤텍스 대신 세마포어로 임계영역을 관리했다.
#include <semaphore.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <pthread.h>
#define MAX_THREAD_NUM 2
int count = 0;
sem_t mysem;
void *t_function(void *data)
{
pthread_t id;
int tmp;
id = pthread_self();
printf("Thread %lu Created.\n", id);
while(1)
{
sem_wait(&mysem);
tmp = count;
tmp = tmp + 1;
sleep(1);
count = tmp;
printf("%lu : %d\n", id, count);
sem_post(&mysem);
usleep(1);
}
}
int main(int argc, char **argv)
{
pthread_t p_thread[MAX_THREAD_NUM];
int thr_id;
int status;
int i = 0;
if (sem_init(&mysem, 0, 1) == -1)
{
perror("Error");
exit(0);
}
for( i = 0; i < MAX_THREAD_NUM; i++)
{
// 쓰레드 생성 아규먼트로 2 를 넘긴다.
thr_id = pthread_create(&p_thread[i], NULL, t_function, (void *)&i);
if (thr_id < 0)
{
perror("thread create error : ");
exit(0);
}
}
pthread_join(p_thread[0], NULL);
pthread_join(p_thread[1], NULL);
return 0;
}
3.7 이름있는 세마포어 예제
세마포어 생산자
#include <semaphore.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <stdlib.h>
#include <stdio.h>
const char *countFile = "count.db";
int main(int argc, char **argv)
{
int count = 100;
int fd;
sem_t *mysem;
sem_unlink("mysem");
if((mysem = sem_open("mysem", O_CREAT, 0777, 1)) == NULL)
{
perror("Sem Open Error");
return 1;
}
if( (fd = open(countFile,O_CREAT|O_RDWR, S_IRUSR|S_IWUSR )) == -1)
{
perror("Open Error\n");
return 1;
}
while(1)
{
sem_wait(mysem);
lseek(fd, 0, SEEK_SET);
read(fd, (void *)&count, sizeof(count));
printf("Read Data %d\n",count);
count++;
lseek(fd, 0, SEEK_SET);
write(fd, (void *)&count, sizeof(count));
sem_post(mysem);
sleep(1);
}
close(fd);
}
소비자
#include <semaphore.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <stdlib.h>
#include <stdio.h>
const char *countFile = "count.db";
int main(int argc, char **argv)
{
int count = 100;
int fd;
sem_t *mysem;
if((mysem = sem_open("mysem", 0, 0777, 0)) == SEM_FAILED)
{
perror("Sem Open Error");
return 1;
}
if( (fd = open(countFile,O_RDWR)) == -1)
{
perror("Open Error\n");
return 1;
}
while(1)
{
sem_wait(mysem);
lseek(fd, 0, SEEK_SET);
read(fd, (void *)&count, sizeof(count));
printf("Read Data %d\n",count);
count++;
lseek(fd, 0, SEEK_SET);
write(fd, (void *)&count, sizeof(count));
sem_post(mysem);
sleep(1);
}
close(fd);
}
4 결론
fcntl()이용한 잠금으로도 세마포어와 비슷한 일을 수행할 수 있는데, fcntl보다 좀더 세밀한 조정이 가능하다라는 장점을 가지고 있다. 세밀한 만큼, 간단한 일을 하기에는 지나치게 복잡한 면이 있으니, 상황에 따라서 적절하게 선택하면 된다.
fcntl의 잠금을 이용한 자원접근 제어는 fcntl을 이용한 파일/레코드 잠금 문서를 참고하기 바란다.
리눅스에서의 세마포어(2)
등록일 : 2007년 07월 03일 조회수 : 13,206

제공 : 한빛 네트워크
저자 : Vikram Shukla
역자 : 주재경
원문 : Semaphores in Linux
[이전 기사 보기]
리눅스에서의 세마포어(1)
POSIX 세마포어
System V 세마포어에 대한 잠재적인 학습곡선이 POSIX 세마포어에 비해 훨씬 높다. 당신이 이 부분을 본 후 이전 장에서 당신이 배운 것과 비교해 보면 더욱 쉽게 이해 될 것이다.
POSIX는 세마포어에 대한 동작, 생성, 초기화에 대한 사용법이 간단하다. 프로세스간 통신을 제어하는 훨씬 효과적인 방법을 제공한다. POSIX는 2가지 종류 named 세마포어와 unnamed 세마포어를 가지고 있다.
Named 세마포어
man 페이지를 보면 named 세마포어는 System V 세마포어처럼 이름으로 구분된다는 것을 알 수 있을 것이다. System V와 같은 세마포어는 시스템 전체에 걸쳐 영향을 미치며 임의의 순간에 활성화 될 수 있는 세마포어 수가 제한된다.
named 세마포어는 아래의 함수 호출로 생성 된다 :
서로 구분되는 세마포어의 이름
oflag
세마포어 생성을 위해서 O_CREAT로 설정된다(이미 세마포어가 존재하는 경우 함수 호출을 실패로 하는 경우 O_EXCL로 설정한다)
mode_t
새로운 세마포어에 대한 허가권을 제어한다.
value
세마포어의 초기 값을 결정한다.
한 번의 호출로 세마포어를 생성, 초기화, 허가권을 설정하며 이는 System V 세마포어 동작과는 아주 다르다. 이것이 본질적으로 더욱 분명하고 atomic하다. System V 세마포어 가 int형(open()함수가 리턴하는 fd와 비슷하게)으로 스스로를 구분한다는 면에서 또 다른 차이점이 있으며 반면에 sem_open함수는 POSIX 세마포어의 구분자로 동작하는 sem_t를 리턴한다.
이제부터 세마포어에 대한 동작이 이루어진다. 세마포어를 locking하는 방법은:
세마포어를 unlocking하는 방법은
일단 세마포어 사용을 완료했으면 이 사용을 해제(destroy)하는 것이 중요하다. named 세마포어에 대한 모든 참조는 종료 전이나 종료 핸들러가 sem_unlink()를 호출하는 범위 내에서 세마포어를 시스템에서 제거한 다음에 sem_close() 함수를 호출하여 종료한다. 주목해야 할 것은, 프로세스나 쓰레드가 세마포어를 참조한다면 sem_unlink() 함수는 영향을 끼치지 못한다는 점이다.
Unnamed 세마포어
man 페이지에 따르면 unnamed 세마포어는 다중쓰레드(쓰레드 공유 세마포어)나 프로세스(프로세스 공유 세마포어)가 공유하는 메모리 영역에 위치하고 있다. 쓰레드 공유 세마포어 프로세스의 쓰레드만이 공유하는 영역(예를 들면 전역변수)에 위치한다. 프로세스 공유 세마포어는 서로 다른 프로세스가 공유 할 수 있는 영역(예를 들어 공유메모리와 같은)에 위치한다. Unnamed 세마포어는 쓰레드들 간 그리고 관련 프로세스들 간의 동기화를 제공한다.
Unnamed 세마포어는 sem_open 호출이 필요하지 않다. 대신에 아래의 2가지 호출이 필요하다.
이 인자는 임의의 프로세스의 쓰레들 사이에 혹은 프로세스들 사이에 세마포어가 공유되는지 어떤지를 표시한다. 만약 pshared 값이 0이라면 세마포어는 프로세스의 쓰레드들 간에 공유된다. Pshared가 0이 아니면 세마포어는 프로세스 간에 공유된다.
value
초기화될 때 세마포어가 가지는 값
세마포어가 초기화 되자마자 프로그래머는 sem_t 타입의 세마포어를 사용할 수 있다. 세마포어에 대한 lock과 unlock 동작은 앞서 본 바와 같이 sem_wait(sem_t *sem)와 sem_post(sem_t *sem)을 통해 이루어 진다.
이 글의 마지막 장은 POSIX 세마포어를 사용하여 개발된 간단한 worker-consumer 문제를 설명한다.
System V 세마포어와 POSIX 세마포어
System V 와 POSIX 세마포어 사이에는 많은 차이점이 있다.
동기화 매커니즘에 대한 세마포어의 잇점은 같은 리소스에 접근 하고자 하는 2개의 관련된 혹은 관련되지 않은 프로세스를 동기화 하기 위해 사용될 수 있다는 점이다.
related 프로세스
새로운 프로세스가 이미 있는 프로세스 내에서 생성되면 이 프로세스를 related 프로세스라 한다. 아래의 예제는 관련 프로세스가 어떻게 동기화 되는지를 보여준다.
Unrelated 프로세스
2개 프로세스가 서로에 대해 전혀 알려져 있지 않고 이들 사이에 어떤 관련성도 없을 때 이를 관련이 없다(unrelated)라고 얘기한다. 예를 들면 2개의 서로 다른 프로그램의 인스턴스는 관련없는(unrelated) 프로세스이다. 이런 프로그램이 공유 자원을 접근하는 경우 세마포어가 이들 접근의 동기화를 위해 사용될 수 있다. 아래의 소스 코드는 이를 설명한다.
위의 프로그램에 덧붙여 말하자면 세마포어는 리소스 접근을 위해 서로 협조하여 사용될 수 있다. 세마포어는 뮤텍스가 아님에 유의하라. 뮤텍스는 리소스에 순차적인 접근을 허용한다. 반면에 세마포어는 순차적인 접근에 덧붙여 병렬적으로 리소스를 접근하는데 사용된다. 예를 들어 n명의 사용자가 접근 가능한 리소스 R을 생각해 보자. 뮤텍스를 사용하는 경우 리소스를 lock 그리고 unlock하기 위해 뮤텍스 m이 필요하다. 그러므로 리소스 R을 사용하기 위해 한 번에 단지 한 명의 사용자만이 가능하다. 반면에 세마포어는 n명의 사용자가 리소스 R을 동기적으로 접근하는 것을 가능하게 한다. 가장 일반적인 예가 Toilet 예제이다.
세마포어의 다른 이점은 개발자가 메모리 내에 맵핑 될 수 있는 혹은 실행 할 수 있는 실행 객체의 실행횟수를 제한할 필요가 있는 상황에 있다. 간단한 예를 보자.
위의 소스를 보면 꽤 분명한 차이점이 나타난다. 세마포어와 뮤텍스 사이의 또 다른 확연한 차이점을 가지고 여기서 차이점에 대해 다시 한번 설명하고자 한다.
생산자 소비자 문제는 세마포어의 중요성을 알려주는 아주 오래된 문제이다. 전통적인 생산자 소비자 문제를 살펴보고 이의 간단한 해법도 살펴보자. 얘기할 시나리오는 그리 복잡하지 않다.
2개의 프로세스가 있다: 생산자와 소비자. 생산자는 정보를 데이터 영역에 집어넣는다. 반면에 소비자는 같은 영역의 정보를 소비한다. 생산자가 데이터 영역에 정보를 입력하기 위해서는 충분한 공간이 있어야만 한다. 생산자의 역할은 데이터 영역에 데이터를 입력하는 것이다. 이와 비슷하게 소비자의 역할은 데이터 영역의 정보를 제거하는 것이다. 간단히 말해 생산자는 데이터 영역에서 소비자의 영역 확보에 따라 더 많은 정보를 넣을 수 있다, 반면에 소비자는 생산자가 데이터 영역에 데이터를 넣는 것에 따라 정보를 제거할 수 있다.
이 시나리오를 개발하기 위해 생산자와 소비자가 통신 할 수 있는 매커니즘이 필요하다. 그래서 생산자 소비자는 언제 데이터 영역에서 데이터를 읽고 쓰기를 해야 안전한지를 안다. 이를 하기 위해 사용되는 매커니즘이 세마포어 이다.
아래의 코드에서 데이터 영역은 buffer[BUFF_SIZE]로 정의되고 버퍼 크기는 #define BUFF_SIZE 4로 정의된다. 생산자 소비자 모두 이 데이터 영역에 접근한다. 데이터 영역의 크기는 4로 제한된다. 시그널을 위해서는 POSIX 세마포어가 사용되고 있다.
세마포어와 뮤텍스의 차이점 뿐만 아니라 세마포어의 다양한 종류에 대해서도 살펴보았다. 개발자가 뮤텍스를 사용할지 세마포어를 사용할지를 결정하고자 할 때 그리고 System V와 POSIX 세마포어 사이의 전환에 이 글은 도움을 준다. 위 예제에서 사용된 API에 대한 좀더 상세한 설명은 관련 man 페이지를 참조하라.
참조
http://www.dcs.ed.ac.uk/home/adamd/essays/ex1.html
http://www.die.net/doc/linux/man/man7/sem_overview.7.html
http://www.csc.villanova.edu/~mdamian/threads/posixsem.html
http://www.cim.mcgill.ca/~franco/OpSys-304-427/lecture-notes/node31.html
리눅스 맨 페이지
리눅스 커널 문서
저자 Vikram shukla는 7년반 이상의 객체 기반 언어를 사용한 개발에 대한 경험을 가지고 있으며 현재 뉴저지의 Logic Planet에서 컨설턴트로 일하고 있다.
역자 주재경님은 현재 (주)세기미래기술에 근무하고 있으며 리눅스, 네트워크, 운영체제 및 멀티미디어 코덱에 관심을 가지고 있습니다.
저자 : Vikram Shukla
역자 : 주재경
원문 : Semaphores in Linux
[이전 기사 보기]
리눅스에서의 세마포어(1)
POSIX 세마포어
System V 세마포어에 대한 잠재적인 학습곡선이 POSIX 세마포어에 비해 훨씬 높다. 당신이 이 부분을 본 후 이전 장에서 당신이 배운 것과 비교해 보면 더욱 쉽게 이해 될 것이다.
POSIX는 세마포어에 대한 동작, 생성, 초기화에 대한 사용법이 간단하다. 프로세스간 통신을 제어하는 훨씬 효과적인 방법을 제공한다. POSIX는 2가지 종류 named 세마포어와 unnamed 세마포어를 가지고 있다.
Named 세마포어
man 페이지를 보면 named 세마포어는 System V 세마포어처럼 이름으로 구분된다는 것을 알 수 있을 것이다. System V와 같은 세마포어는 시스템 전체에 걸쳐 영향을 미치며 임의의 순간에 활성화 될 수 있는 세마포어 수가 제한된다.
named 세마포어는 아래의 함수 호출로 생성 된다 :
sem_t *sem_open(const char *name, int oflag, mode_t mode , int value);name
서로 구분되는 세마포어의 이름
oflag
세마포어 생성을 위해서 O_CREAT로 설정된다(이미 세마포어가 존재하는 경우 함수 호출을 실패로 하는 경우 O_EXCL로 설정한다)
mode_t
새로운 세마포어에 대한 허가권을 제어한다.
value
세마포어의 초기 값을 결정한다.
한 번의 호출로 세마포어를 생성, 초기화, 허가권을 설정하며 이는 System V 세마포어 동작과는 아주 다르다. 이것이 본질적으로 더욱 분명하고 atomic하다. System V 세마포어 가 int형(open()함수가 리턴하는 fd와 비슷하게)으로 스스로를 구분한다는 면에서 또 다른 차이점이 있으며 반면에 sem_open함수는 POSIX 세마포어의 구분자로 동작하는 sem_t를 리턴한다.
이제부터 세마포어에 대한 동작이 이루어진다. 세마포어를 locking하는 방법은:
int sem_wait(sem_t *sem);이 함수 호출은 세마포어 카운트가 0보다 큰 경우 세마포어를 lock한다. 세마포어를 locking한 후 카운트는 1만큼 감소한다. 세마포어 카운트가 0인 경우 함수 호출은 block된다.
세마포어를 unlocking하는 방법은
int sem_post(sem_t *sem);이 함수 호출은 세마포어 카운트를 1만큼 증가 시키고 리턴한다.
일단 세마포어 사용을 완료했으면 이 사용을 해제(destroy)하는 것이 중요하다. named 세마포어에 대한 모든 참조는 종료 전이나 종료 핸들러가 sem_unlink()를 호출하는 범위 내에서 세마포어를 시스템에서 제거한 다음에 sem_close() 함수를 호출하여 종료한다. 주목해야 할 것은, 프로세스나 쓰레드가 세마포어를 참조한다면 sem_unlink() 함수는 영향을 끼치지 못한다는 점이다.
Unnamed 세마포어
man 페이지에 따르면 unnamed 세마포어는 다중쓰레드(쓰레드 공유 세마포어)나 프로세스(프로세스 공유 세마포어)가 공유하는 메모리 영역에 위치하고 있다. 쓰레드 공유 세마포어 프로세스의 쓰레드만이 공유하는 영역(예를 들면 전역변수)에 위치한다. 프로세스 공유 세마포어는 서로 다른 프로세스가 공유 할 수 있는 영역(예를 들어 공유메모리와 같은)에 위치한다. Unnamed 세마포어는 쓰레드들 간 그리고 관련 프로세스들 간의 동기화를 제공한다.
Unnamed 세마포어는 sem_open 호출이 필요하지 않다. 대신에 아래의 2가지 호출이 필요하다.
{
sem_t semid;
int sem_init(sem_t *sem, int pshared, unsigned value);
}
pshared이 인자는 임의의 프로세스의 쓰레들 사이에 혹은 프로세스들 사이에 세마포어가 공유되는지 어떤지를 표시한다. 만약 pshared 값이 0이라면 세마포어는 프로세스의 쓰레드들 간에 공유된다. Pshared가 0이 아니면 세마포어는 프로세스 간에 공유된다.
value
초기화될 때 세마포어가 가지는 값
세마포어가 초기화 되자마자 프로그래머는 sem_t 타입의 세마포어를 사용할 수 있다. 세마포어에 대한 lock과 unlock 동작은 앞서 본 바와 같이 sem_wait(sem_t *sem)와 sem_post(sem_t *sem)을 통해 이루어 진다.
이 글의 마지막 장은 POSIX 세마포어를 사용하여 개발된 간단한 worker-consumer 문제를 설명한다.
System V 세마포어와 POSIX 세마포어
System V 와 POSIX 세마포어 사이에는 많은 차이점이 있다.
- System V와 POSIX 세마포어에서 한 가지 확연한 차이점은 System V에서는 세마포어 카운터의 증가 혹은 감소량을 사용자가 제어 할 수 있지만 POSIX에서는 증가 감소가 1만큼 이루어 진다.
- POSIX 세마포어는 세마포어 허가권 조작을 허용하지 않지만 System V 세마포어는 최초 허가권의 부분 집합에 대해 세마포어 허가권을 변경할 수 있다.
- POSIX 세마포어의 생성과 기화는 유저의 관점에서 최소 단위 동작(atomic)이다.
- 사용면에서 System V 세마포어는 좀 어색한 면이 있고 반면에 POSIX 세마포어는 직접적이다.
- unnmaed 세마포어를 사용하는 POSIX 세마포어의 범위는 System V 세마포어의 범위보다 훨씬 더 크다. 사용자/클라이언트 시나리오에서 각 사용자가 서버에 대한 인스턴스를 가지고 있는 경우 POSIX 세마포어를 사용하는 것이 더 좋다.
- 세마포어를 생성할 때 System V 세마포어는 세마포어 배열을 생성한다. 반면에 POSIX 세마포어는 단지 하나만 생성한다. 이를 이유로 인해 세마포어 생성(메모리 측면에서)은 POSIX 세마포어와 비교했을 때 System V 세마포어의 비용이 더 들어간다.
- POSIX 세마포어의 성능이 System V 기반의 세마포어 보다 더 좋다고 말했다.
- POSIX 세마포어는 시스템 전체에 걸친 세마포어 보다는 프로세스 전체에 걸친 매커니즘을 제공한다. 그래서 개발자가 세마포어를 close하는 동작을 잊는다면 세마포어 cleanup은 프로세스 종료 시점에서 이루어진다. 간단히 말해 POSIX 세마포어는 일관되지 않은 매커니즘을 제공한다.
동기화 매커니즘에 대한 세마포어의 잇점은 같은 리소스에 접근 하고자 하는 2개의 관련된 혹은 관련되지 않은 프로세스를 동기화 하기 위해 사용될 수 있다는 점이다.
related 프로세스
새로운 프로세스가 이미 있는 프로세스 내에서 생성되면 이 프로세스를 related 프로세스라 한다. 아래의 예제는 관련 프로세스가 어떻게 동기화 되는지를 보여준다.
#include <semaphore.h>
#include <stdio.h>
#include <errno.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/mman.h>
int main(int argc, char **argv)
{
int fd, i,count=0,nloop=10,zero=0,*ptr;
sem_t mutex;
//파일을 열고 메모리와 매핑한다.
fd = open("log.txt",O_RDWR|O_CREAT,S_IRWXU);
write(fd,&zero,sizeof(int));
ptr = mmap(NULL,sizeof(int),PROT_READ |PROT_WRITE,MAP_SHARED,fd,0);
close(fd);
/* 세마포어를 생성화고 초기화 한다. */
if( sem_init(&mutex,1,1) < 0)
{
perror("semaphore initilization");
exit(0);
}
if (fork() == 0) { /* child process*/
for (i = 0; i < nloop; i++) {
sem_wait(&mutex);
printf("child: %dn", (*ptr)++);
sem_post(&mutex);
}
exit(0);
}
/* 부모 프로세스로 돌아간다. */
for (i = 0; i < nloop; i++) {
sem_wait(&mutex);
printf("parent: %dn", (*ptr)++);
sem_post(&mutex);
}
exit(0);
}
이 예제에서 related 프로세스는 동기화된 메모리를 엑세스한다. Unrelated 프로세스
2개 프로세스가 서로에 대해 전혀 알려져 있지 않고 이들 사이에 어떤 관련성도 없을 때 이를 관련이 없다(unrelated)라고 얘기한다. 예를 들면 2개의 서로 다른 프로그램의 인스턴스는 관련없는(unrelated) 프로세스이다. 이런 프로그램이 공유 자원을 접근하는 경우 세마포어가 이들 접근의 동기화를 위해 사용될 수 있다. 아래의 소스 코드는 이를 설명한다.
<u>File1: server.c </u>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <stdio.h>
#include <semaphore.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define SHMSZ 27
char SEM_NAME[]= "vik";
int main()
{
char ch;
int shmid;
key_t key;
char *shm,*s;
sem_t *mutex;
//name the shared memory segment
key = 1000;
//세마포어 생성과 초기화
mutex = sem_open(SEM_NAME,O_CREAT,0644,1);
if(mutex == SEM_FAILED)
{
perror("unable to create semaphore");
sem_unlink(SEM_NAME);
exit(-1);
}
//이 key로 공유메모리 생성
shmid = shmget(key,SHMSZ,IPC_CREAT|0666);
if(shmid<0)
{
perror("failure in shmget");
exit(-1);
}
//이 조각을 가상 메모리에 덧붙인다.
shm = shmat(shmid,NULL,0);
//메모리에 쓰기 시작
s = shm;
for(ch='A';ch<='Z';ch++)
{
sem_wait(mutex);
*s++ = ch;
sem_post(mutex);
}
//아래 루프는 이진 세마포어로 대체 가능하다
while(*shm != '*')
{
sleep(1);
}
sem_close(mutex);
sem_unlink(SEM_NAME);
shmctl(shmid, IPC_RMID, 0);
_exit(0);
}
<u>File 2: client.c</u>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <stdio.h>
#include <semaphore.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define SHMSZ 27
char SEM_NAME[]= "vik";
int main()
{
char ch;
int shmid;
key_t key;
char *shm,*s;
sem_t *mutex;
//name the shared memory segment
key = 1000;
//세마포어 생성 초기화
mutex = sem_open(SEM_NAME,0,0644,0);
if(mutex == SEM_FAILED)
{
perror("reader:unable to execute semaphore");
sem_close(mutex);
exit(-1);
}
//이 key를 사용하여 공유메모리 생성
shmid = shmget(key,SHMSZ,0666);
if(shmid<0)
{
perror("reader:failure in shmget");
exit(-1);
}
//이 조각을 가상 메모리에 덧 붙인다.
shm = shmat(shmid,NULL,0);
//start reading
s = shm;
for(s=shm;*s!=NULL;s++)
{
sem_wait(mutex);
putchar(*s);
sem_post(mutex);
}
//다른 세마포어로 대체가능
*shm = '*';
sem_close(mutex);
shmctl(shmid, IPC_RMID, 0);
exit(0);
}
위의 코드(클라이언트/서버)는 완전히 서로 다른 프로세스 사이에서 세마포어가 어떻게 사용될 수 있는지를 설명한다. 위의 프로그램에 덧붙여 말하자면 세마포어는 리소스 접근을 위해 서로 협조하여 사용될 수 있다. 세마포어는 뮤텍스가 아님에 유의하라. 뮤텍스는 리소스에 순차적인 접근을 허용한다. 반면에 세마포어는 순차적인 접근에 덧붙여 병렬적으로 리소스를 접근하는데 사용된다. 예를 들어 n명의 사용자가 접근 가능한 리소스 R을 생각해 보자. 뮤텍스를 사용하는 경우 리소스를 lock 그리고 unlock하기 위해 뮤텍스 m이 필요하다. 그러므로 리소스 R을 사용하기 위해 한 번에 단지 한 명의 사용자만이 가능하다. 반면에 세마포어는 n명의 사용자가 리소스 R을 동기적으로 접근하는 것을 가능하게 한다. 가장 일반적인 예가 Toilet 예제이다.
세마포어의 다른 이점은 개발자가 메모리 내에 맵핑 될 수 있는 혹은 실행 할 수 있는 실행 객체의 실행횟수를 제한할 필요가 있는 상황에 있다. 간단한 예를 보자.
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <stdio.h>
#include <errno.h>
#define KEY 0x100
typedef union semun
{
int val;
struct semid_ds *st;
ushort * array;
}semun_t;
int main()
{
int semid,count;
struct sembuf op;
semid = semget((key_t)KEY,10,0666|IPC_CREAT);
if(semid==-1)
{
perror("error in creating semaphore, Reason:");
exit(-1);
}
count = semctl(semid,0,GETVAL);
if(count>2)
{
printf("Cannot execute Process anymoren");
_exit(1);
}
//세마포어를 얻고 다음 단계로 진행한다.
op.sem_num = 0; //0번째 세마포어를 표시
op.sem_op = 1; //락을 위해 세마포어 카운터 감소시킴
op.sem_flg = 0; //락을 얻기까지 기다림
if( semop(semid,&op,1)==-1)
{
perror("semop failed : Reason");
if(errno==EAGAIN)
printf("Max allowed process exceededn");
}
//실질적인 시작은 여기서 이루어진다.
sleep(10);
return 1;
}
세마포어와 뮤텍스의 차이점 위의 소스를 보면 꽤 분명한 차이점이 나타난다. 세마포어와 뮤텍스 사이의 또 다른 확연한 차이점을 가지고 여기서 차이점에 대해 다시 한번 설명하고자 한다.
- 세마포어는 뮤텍스가 될 수 있지만 뮤텍스는 세마포어가 될 수 없다. 이는 간단히 말해 이진 세마포어가 뮤텍스로 사용될 수 있음을 의미하며 뮤텍스는 결코 세마포어의 기능을 보여줄 수는 없다.
- 세마포어와 뮤텍스(적어도 최근 커널에서는) 모두는 본래 비 재귀적이다.
- 세마포는 소유할 수 없는 반면 뮤텍스는 소유 가능하며 소유주가 이에 대한 책임을 진다. 이는 디버깅 관점에서 중요한 차이점이다.
- 뮤텍스의 경우에 뮤텍스를 소유하고 있는 쓰레드가 이 뮤텍스를 해제해야 한다. 그러나 세마포어의 경우 이러한 조건이 필요치 않다. 임의의 다른 쓰레드가 함수 sem_post()를 사용하여 세마포어를 해제하기 위한 신호를 보낼 수 있다.
- 정의에 따라 뮤텍스는 하나 이상의 쓰레드에 의해 동시에 실행되지 않도록 재진입코드 부분에 대한 접근을 시리얼화 하기 위해 사용한다.
- 개발자에게 중요한 또 다른 차이점은 세마포어는 시스템 범위에 걸쳐 있고 파일시스템상의 파일 형태로 존재한다는 점이다. 뮤텍스는 프로세스 범위를 가지며 프로세스가 종료될 때 자동으로 clean up된다.
- 세마포어의 본래 목적은 쓰레드 뿐만 아니라 관련 혹은 비 관련 프로세스를 동기화 하는데 있다. 뮤텍스는 쓰레드간의 동기화에만 사용되며 최대 관련(related)프로세스(최근 커널의 pthread구현은 뮤텍스가 related 프로세스간에도 사용 가능하게 한다.)
- 커널 문서에 따르면 뮤텍스가 세마포어에 비해 더 가볍다. 이것이 의미하는 바는 세마포어를 사용하는 프로그램이 뮤텍스를 사용하는 프로그램에 비해 좀더 많은 메모리를 사용함을 의미한다.
- 사용면에서 봤을 때 뮤텍스가 세마포어에 비해 좀더 간단한 사용법을 갖는다.
생산자 소비자 문제는 세마포어의 중요성을 알려주는 아주 오래된 문제이다. 전통적인 생산자 소비자 문제를 살펴보고 이의 간단한 해법도 살펴보자. 얘기할 시나리오는 그리 복잡하지 않다.
2개의 프로세스가 있다: 생산자와 소비자. 생산자는 정보를 데이터 영역에 집어넣는다. 반면에 소비자는 같은 영역의 정보를 소비한다. 생산자가 데이터 영역에 정보를 입력하기 위해서는 충분한 공간이 있어야만 한다. 생산자의 역할은 데이터 영역에 데이터를 입력하는 것이다. 이와 비슷하게 소비자의 역할은 데이터 영역의 정보를 제거하는 것이다. 간단히 말해 생산자는 데이터 영역에서 소비자의 영역 확보에 따라 더 많은 정보를 넣을 수 있다, 반면에 소비자는 생산자가 데이터 영역에 데이터를 넣는 것에 따라 정보를 제거할 수 있다.
이 시나리오를 개발하기 위해 생산자와 소비자가 통신 할 수 있는 매커니즘이 필요하다. 그래서 생산자 소비자는 언제 데이터 영역에서 데이터를 읽고 쓰기를 해야 안전한지를 안다. 이를 하기 위해 사용되는 매커니즘이 세마포어 이다.
아래의 코드에서 데이터 영역은 buffer[BUFF_SIZE]로 정의되고 버퍼 크기는 #define BUFF_SIZE 4로 정의된다. 생산자 소비자 모두 이 데이터 영역에 접근한다. 데이터 영역의 크기는 4로 제한된다. 시그널을 위해서는 POSIX 세마포어가 사용되고 있다.
#include <pthread.h>
#include <stdio.h>
#include <semaphore.h>
#define BUFF_SIZE 4
#define FULL 0
#define EMPTY 0
char buffer[BUFF_SIZE];
int nextIn = 0;
int nextOut = 0;
sem_t empty_sem_mutex; //생산자 세마포어
sem_t full_sem_mutex; //소비자 세마포어
void Put(char item)
{
int value;
sem_wait(&empty_sem_mutex); //버퍼를 채우기 위한 뮤텍스 획득
buffer[nextIn] = item;
nextIn = (nextIn + 1) % BUFF_SIZE;
printf("Producing %c ...nextIn %d..Ascii=%dn",item,nextIn,item);
if(nextIn==FULL)
{
sem_post(&full_sem_mutex);
sleep(1);
}
sem_post(&empty_sem_mutex);
}
void * Producer()
{
int i;
for(i = 0; i < 10; i++)
{
Put((char)('A'+ i % 26));
}
}
void Get()
{
int item;
sem_wait(&full_sem_mutex); //버퍼에서 소비할 뮤텍스 획득
item = buffer[nextOut];
nextOut = (nextOut + 1) % BUFF_SIZE;
printf("t...Consuming %c ...nextOut %d..Ascii=%dn",item,nextOut,item);
if(nextOut==EMPTY) //its empty
{
sleep(1);
}
sem_post(&full_sem_mutex);
}
void * Consumer()
{
int i;
for(i = 0; i < 10; i++)
{
Get();
}
}
int main()
{
pthread_t ptid,ctid;
//세마포어 초기화
sem_init(&empty_sem_mutex,0,1);
sem_init(&full_sem_mutex,0,0);
//생산자 소비자 쓰레드 생성
if(pthread_create(&ptid, NULL,Producer, NULL))
{
printf("n ERROR creating thread 1");
exit(1);
}
if(pthread_create(&ctid, NULL,Consumer, NULL))
{
printf("n ERROR creating thread 2");
exit(1);
}
if(pthread_join(ptid, NULL)) /* 생산자가 끝나기를 기다림*/
{
printf("n ERROR joining thread");
exit(1);
}
if(pthread_join(ctid, NULL)) /* 소비자가 끝나기를 기다림*/
{
printf("n ERROR joining thread");
exit(1);
}
sem_destroy(&empty_sem_mutex);
sem_destroy(&full_sem_mutex);
//main 쓰레드 종료
pthread_exit(NULL);
return 1;
}
결론 세마포어와 뮤텍스의 차이점 뿐만 아니라 세마포어의 다양한 종류에 대해서도 살펴보았다. 개발자가 뮤텍스를 사용할지 세마포어를 사용할지를 결정하고자 할 때 그리고 System V와 POSIX 세마포어 사이의 전환에 이 글은 도움을 준다. 위 예제에서 사용된 API에 대한 좀더 상세한 설명은 관련 man 페이지를 참조하라.
참조
http://www.dcs.ed.ac.uk/home/adamd/essays/ex1.html
http://www.die.net/doc/linux/man/man7/sem_overview.7.html
http://www.csc.villanova.edu/~mdamian/threads/posixsem.html
http://www.cim.mcgill.ca/~franco/OpSys-304-427/lecture-notes/node31.html
리눅스 맨 페이지
리눅스 커널 문서
저자 Vikram shukla는 7년반 이상의 객체 기반 언어를 사용한 개발에 대한 경험을 가지고 있으며 현재 뉴저지의 Logic Planet에서 컨설턴트로 일하고 있다.
역자 주재경님은 현재 (주)세기미래기술에 근무하고 있으며 리눅스, 네트워크, 운영체제 및 멀티미디어 코덱에 관심을 가지고 있습니다.
* e-mail : jkjoo@segifuture.com
'Programming > Linux_Kernel' 카테고리의 다른 글
| linux 에서 page cache(페이지 캐쉬)란? (0) | 2014.04.24 |
|---|---|
| linux kernel 에서 사용 할 수 있는 file io functions (0) | 2014.04.18 |
| 사용가용한 physical memory block 을 얻어오는 방법 (0) | 2014.04.07 |
| poll, sysfs sample code (0) | 2014.04.07 |
| class 에 sysfs node 등록하여 사용하기 (0) | 2014.04.02 |